
From “Recording Hardware” to “Bounded Reality Memory Infrastructure”
— A Three-Year Track Analysis of AI Recording Devices from the Perspective of Privacy Constraints, First Principles, and the Rise of IM-Agent
Abstract
In the next three years, AI recording devices will evolve from niche hardware into a super track, not because “recording” itself suddenly becomes attractive, but because it fills a critical input layer missing for AI to enter the real world: continuous, low-friction, context-rich human dialogue data.
At the same time, improvements in speech recognition and real-time audio interaction capabilities allow sound to be reliably transformed into retrievable, summarizable, and executable data for the first time; trends like OpenClaw, Claude in Slack, and MCP indicate that the main battlefield for AI is not a new isolated app, but rather the chat and collaboration flows that people already use daily. The true competitive edge lies not in who creates a smaller recording device, but in who can weave recording devices, memory systems, IM interfaces, permission systems, and execution toolchains into a privacy-compliant closed loop. Thus, privacy is not a side effect but the boundary of the market; it is not a compliance cost but the product structure itself.
1. The True Subject of the Problem: Not Recording, but the Right to Capture “Real World Context”
Common sense suggests that the most important information in human society does not first appear as documents, but rather as dialogue. Decisions happen first in meetings before entering minutes; transactions form first over the phone before entering CRM; diagnoses unfold first in conversation before entering medical records; management is completed first in discussions before entering systems.
In other words, text is often the result, while sound is the process. And the process is more valuable than the result because it contains tone, pauses, hesitations, priorities, emotional intensity, and relationship structures. Slack officially refers to team daily conversations as “the richest context,” noting that the most valuable insights, decisions, and ideas in enterprises often first appear in discussions; the logic behind Anthropic’s launch of MCP is similarly based on a judgment: no matter how powerful the model, if it is isolated from real data sources, it will be trapped in “information islands.”
Therefore, the essence of AI recording devices should not be understood as “a small hardware that can record,” but as sensors for real-world context. What it needs to solve is not “can users leave audio files,” but “can AI obtain a person’s real situation with sufficiently low friction, sufficiently high frequency, and sufficiently reliable methods.”
Once the problem is defined this way, the logic of the track changes completely: it no longer belongs to small innovations in consumer electronics, but is part of the next generation of AI infrastructure. This judgment holds true now because OpenAI’s next-generation speech models have clearly pushed the accuracy and reliability in complex accents, noise, and varying speech rates to a new level, while the Realtime API makes native audio input/output and real-time transcription an engineering feasible capability.
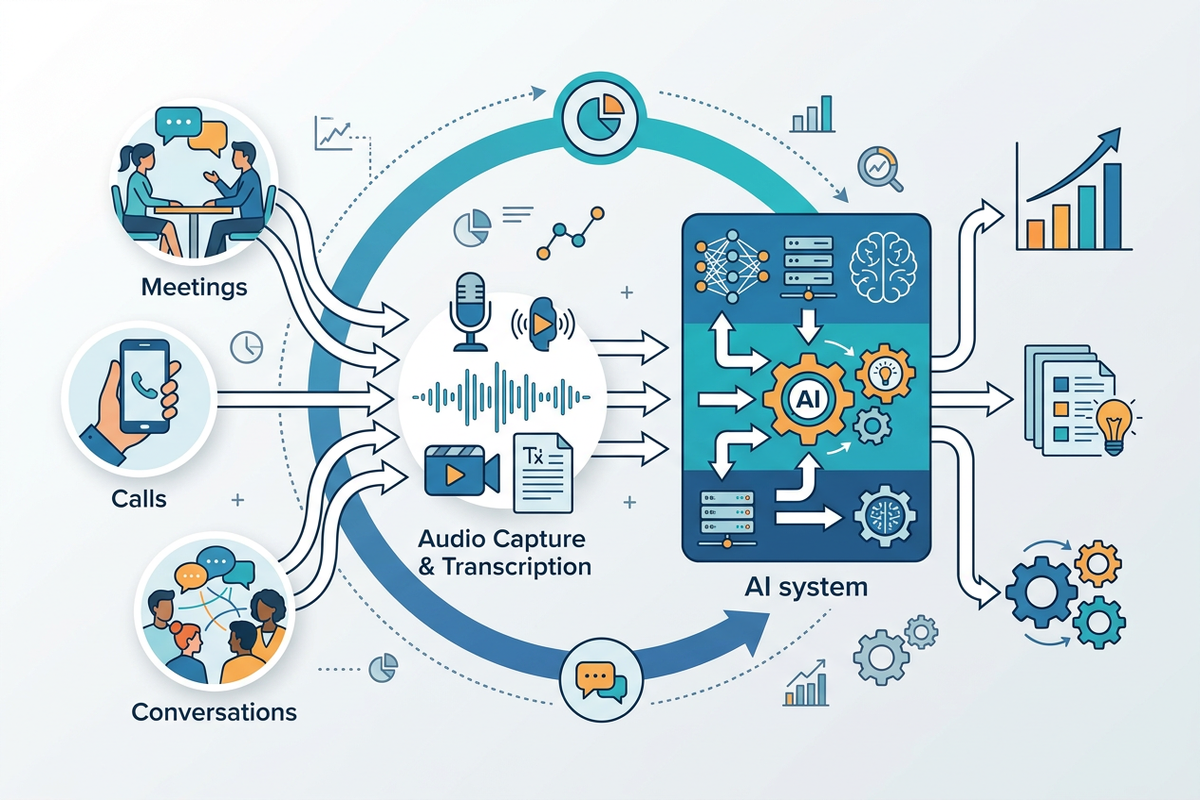
2. Recalculating with Musk’s First Principles: What Are Users Really Buying?
Musk’s first principles approach does not ask “how others do it,” but breaks the problem down to its most fundamental truths and then builds up from there. Musk has summarized this method in several public forums as: do not rely on analogy; instead, “boil” things down to the most basic truth and then deduce upwards.
Using this method to analyze AI recording devices reveals at least four fundamental truths. First, the most natural input of information for humans is not a keyboard, but speaking. Second, truly commercially valuable AI needs not just answers, but context as well. Third, any entry point that can continuously collect context with high frequency and low friction will become a control point for higher-level software and services. Fourth, users will not pay for “recording” in the long term, but will continuously pay for “less forgetting, less leaking, less switching, less reiteration, and less management cost.” Thus, what users are fundamentally buying is not a microphone, but external memory, external attention, and external execution capability.
This also explains why many people misjudge that smartphones are sufficient. Smartphones can certainly record, but they are not inherently suitable for tasks that require “continuous, close, low-disruption, default-on, and stable permissions” for collection.
The value of dedicated devices lies not in whether they provide absolutely new functions, but in whether they can turn a previously marginal behavior into a default behavior. Headphones did not invent listening to music, nor did fitness watches invent step counting; their success lies in making a certain action a habitual background layer. For AI recording devices to become a super track, they must also achieve the same migration: turning “occasional recording” into “default memory,” turning “files” into “streams,” and turning “data” into “contextual assets.” This migration now has a technological foundation to support it.
3. Why the “Rise of Clawdbot Embedded in IM” is a More Important Signal
One easily overlooked point here is that recording devices are not the endgame; IM is the social shell of AI. OpenClaw’s official website defines itself as a personal AI assistant that can be driven through WhatsApp, Telegram, or any existing chat application, emphasizing that it “Runs on Your Machine,” “Private by default,” “Works in DMs and group chats,” and “Persistent Memory.” This means that the Agent no longer requires users to switch to an entirely new software universe, but instead embeds itself into the interpersonal networks, workflows, and notification streams that users already have.
Claude entering Slack follows the same logic: the Slack Marketplace page clearly states that users only need to DM Claude or @Claude in a thread within Slack to invoke AI without leaving their original workflow; Anthropic’s MCP further abstracts this connection into a universal protocol, attempting to transform the connection between AI and data sources, business tools, and development environments from “individual custom interfaces” into “unified protocols.”
Slack’s official description of its new platform as a natural habitat for Agents emphasizes that the richest context comes from team daily conversations, while the RTS API and MCP server provide a way to access session data that complies with permissions, on-demand queries, and does not require bulk exports.
💡 If audio is the perception layer and IM is the interaction layer, what actually creates defensible value?
This article argues that the real opportunity is not standalone recording hardware, but a privacy-compliant closed loop that connects devices, memory, chat interfaces, permissions, and execution.
Structurally, this means that future AI will not only exist in a chat box or a wearable device, but will form a four-layer architecture: devices responsible for perception, IM responsible for interaction, memory layers responsible for continuity, and tool protocols responsible for execution.
A recording device without IM is merely a sampling sensor; an IM Agent without real-world audio input is just a secretary that can only process explicit commands. The former lacks a “social interface,” while the latter lacks “real-world perception.” The combination of the two forms a complete closed loop: IM provides clear intent and organizational context, audio provides implicit context and life flow data, the memory layer melds the two into a continuous persona and ongoing tasks, and the tool layer translates understanding into action. This is the true form of the super track.
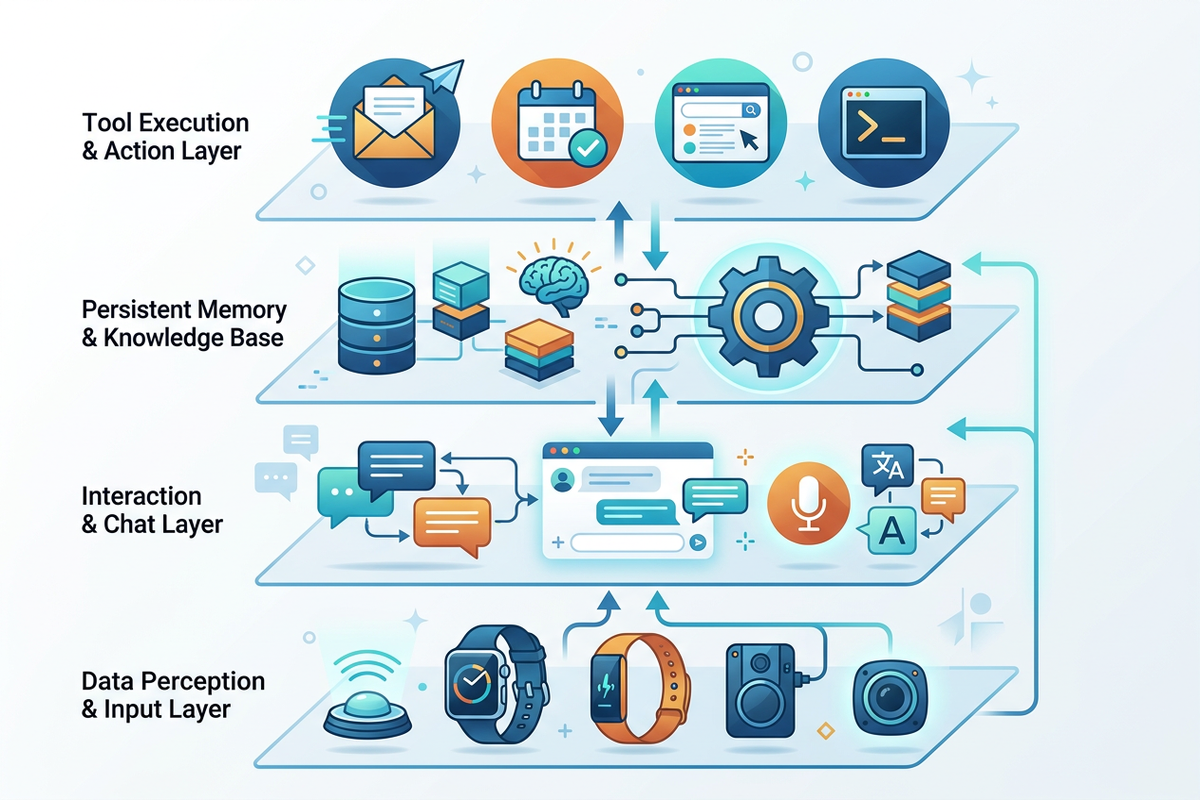
4. Privacy is Not an Obstacle, but the “Constitution” that Determines Who Can Survive
A serious analysis cannot treat privacy as an appendix. Because sound is not just ordinary data; it carries identity, relationships, location, health, emotions, and transaction clues. The EU’s explanation of GDPR principles is very direct: processing personal data must comply with legality, fairness, transparency, purpose limitation, data minimization, storage limitation, and integrity and confidentiality; and the “by design / by default” requirement mandates that companies embed protective measures into systems from the early design stage, defaulting to only processing necessary data, shortening retention periods, and limiting access scope.
NIST’s Privacy Framework and AI RMF also view privacy risks and the design of trustworthy AI within the same framework.
This will directly change the product structure of the track. First, it is not “record everything first and talk later,” but “define the purpose first, then decide what to retain.” Second, it is not “throw all raw audio into the cloud,” but rather process as much as possible at the edge, summarize locally, and upload on demand. Third, it is not “let the model permanently consume all memories,” but allow users to withdraw, delete, set time limits, and grant tiered permissions. Fourth, it is not “default to everyone being visible,” but permissions follow relationship boundaries.
Slack’s official approach to handling conversation data is worth referencing: it emphasizes retrieving only the necessary content on demand, rather than bulk downloading or saving all customer data, and respects existing permission systems, providing Agents with “just enough” context. This approach essentially embodies data minimization in the Agent era.
U.S. regulatory practices have also issued warnings. The FTC’s case against Amazon/Alexa indicates that retaining children’s voice recordings for long periods and violating deletion promises can trigger enforcement and fines; subsequent materials submitted by the FTC to the FCC again highlighted the risks of infringing privacy by training algorithms with highly sensitive voice and video data.
For those developing AI recording devices, this signal is very clear: voice data is not “free fuel,” but a highly constrained managed asset. Additionally, specific recording consent rules vary by jurisdiction. For example, in California, recording “confidential communication” typically requires the consent of all parties involved, while exceptions exist for public situations or where reasonable expectations of being overheard/recorded apply. Those creating products who overlook this will find that the faster they grow, the larger their legal exposure. The following is not legal advice, but the business judgment is simple: the future winners will not be “eavesdropping devices,” but “authorized memory systems.”
5. Another Often Overlooked Reality: Voice Transcription is Still Not “The Truth Itself”
Optimism about the track is fine, but naivety is not. OpenAI’s Realtime documentation clearly warns: audio transcription is completed by an independent ASR process, and the transcribed text may deviate from the model’s actual understanding of the audio, and should only be viewed as a “rough guide.” This statement is critical.
It means that in high-risk scenarios such as healthcare, legal, and compliance audits, “transcribed text” cannot be treated as the final fact; original audio, traceable timestamps, human review, and appeal pathways must all be preserved.
This will not weaken the track; rather, it will reshape the moat. Because as the industry shifts from “can it record” to “can it be used reliably,” the threshold rises from BOM and industrial design to auditability, permission, right to deletion, explainability, and high-risk scenario strategies. Cheap hardware will only allow more people to enter; what will truly eliminate most players will be trustworthy use rather than basic collection. This aligns with the first principle: cheap things do not constitute long-term scarcity; what is scarce is sustainable trust.
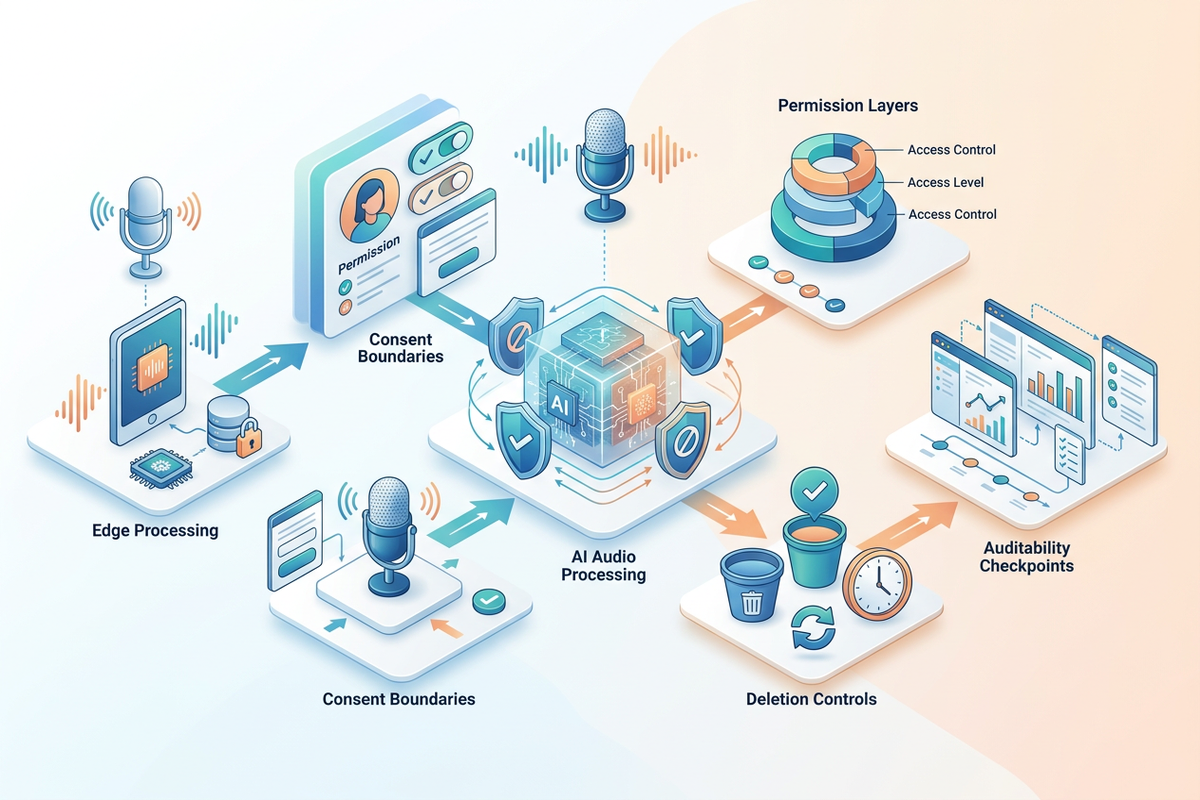
6. Industry Projection for the Next Three Years: How the Track Will Develop
If we put together the above constraints and trends, the most likely outcome in the next three years is not a single blockbuster, but a gradually expanding industry chain. My judgment is: in the first phase, B2B will explode before pure consumer markets because enterprises have a stronger perception of the costs of “omissions, reiterations, handover failures, and context loss,” and are more willing to pay for efficiency and traceability; in the second phase, the personal side will open up in weakly regulated but high-frequency scenarios such as “second brain, personal coach, household affairs agent, health and relationship memory”; in the third phase, true large platforms will integrate wearable audio entry points, Agents within IM, memory layers, and MCP/tool ecosystems to form a normalized system of “hear—remember—understand—execute.”
This projection is not a shot in the dark, but based on several occurrences that have already happened: voice capabilities are available, real-time interaction is available, Agents are entering Slack/chat applications, and session data is being opened to AI in a permission-aware manner by platforms.
Therefore, hardware itself is unlikely to be the ultimate profit driver. Profits will migrate to three areas:
- First, memory governance, which is about who defines retention, deletion, recall, and boundaries;
- Second, context integration, which is about who can stitch audio, IM, documents, calendars, emails, and tool statuses into an executable world model;
- Third, industry workflows, which is about who can turn “what is heard” into high-value actions such as sales advancement, medical records, legal drafts, and on-site service work orders.
To put it plainly: there will be many recording devices, but what is truly valuable is “who possesses trustworthy continuous context.”
Conclusion
Thus, in the next three years, AI recording devices will become a super track, not because they are a novel hardware, but because they stand at the intersection of three structural changes: first, AI is shifting from processing internet data to processing real-world data; second, Agents are migrating from standalone apps to existing social interfaces like IM and collaboration flows; third, privacy is evolving from a legal issue to a product architecture issue.
Musk’s first principles tell us not to view it as “an upgrade of a recording pen,” but as “the sensor layer of a reality memory infrastructure”; signals from OpenClaw and Claude/Slack/MCP tell us that true AI will not only exist within models, but will exist within the communication networks you are already using; privacy regulations and enforcement tell us that the endgame of this track is not “who listens the most,” but “who listens most valuably within legal, minimal, revocable, and auditable boundaries.”
“I’m Trigg — I track how AI infrastructure, privacy constraints, and interface shifts reshape emerging technology markets.”
Explore More AI Industry Analysis
Get more insights on AI hardware, agents, privacy architecture, and the next wave of real-world data infrastructure.
GMIC AI — from hardware to software to field deployment.